
Carbohydrates are a class of molecules utterly crucial for the assembly of complex multicellular organisms which requires interactions among cells. Beside the mediator role in cell-cell, cell-matrix, and cell-molecule interactions, glycans play an essential function in host-pathogen interaction. This is not surprising since all types of cell in nature are covered by a glycocalyx, a sugar shell that could reach the thickness of 100 nm at the apical border of some epithelial cell (Le Pendu et al., 2014).
Cell membranes are built by several molecules, many of which are carrying a set of carbohydrates (glycoconjugates). Each of these sugars consists of a single (monosaccharides) or multiple (oligosaccharide) units. The presentation follows the rule set by the Essential of Glycobiology, which uses the term “glycan” to “refer to any form of mono-, oligo-, polysaccharide, either free or covalently attached to another molecule.
Glycans are linear or branched molecules where each building block is linked to the next using a glycosidic bond. The units which compose glycans are called monosaccharides, and they are identified as units since they cannot be hydrolysed to a simpler form (Varki et al., 2010). A list of all monosaccharides available is shown. However, each biological system can only use a subset of those.

Depending on the stereochemistry of the two building blocks, the glycosidic linkage is defined as α-linkage (same stereochemistry) or β-linkage (different stereochemistry). A variation on the linkage type has a major impact on structural properties and biological functions of oligosaccharides with the same composition. This is evident for starch and cellulose which share the same composition but have a different type of linkages (α1-4 for starch, β1-4 for cellulose). Besides the linkage type, building blocks have multiple attaching points leading to an extensive collection of possible glycan structural configurations.
Elucidating glycan structures is crucial to determine whether they can be recognized by a glycan-binding protein (GBP). These proteins are scanning glycan structures searching for a specific region, defined as glycan determinant. We can imagine this process as the key and lock mechanism introduced by Emil Fischer in 1894 (Cummings, 2009). Blood group antigens (A, B and O) are the first example of glycan determinants, and they give an idea of the importance of glycobiology.
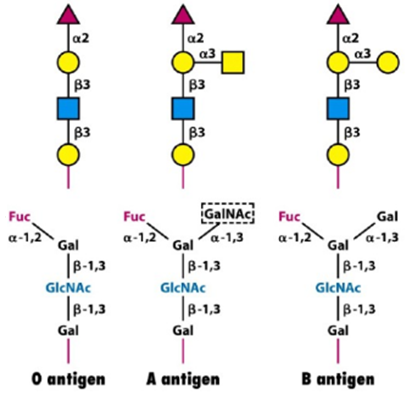
Glycans can freely stand-in body fluids or are attached to other molecules. The combination of a single or multiple glycan(s) with a molecule is named glycoconjugate. In particular, when sugars are attached to proteins, we define the whole as glycoproteins whereas the combination of carbohydrates and lipids are called glycolipids. This article focus on glycans and glycoproteins as the start of a work which will eventually evolve towards glycolipids and proteoglycans.
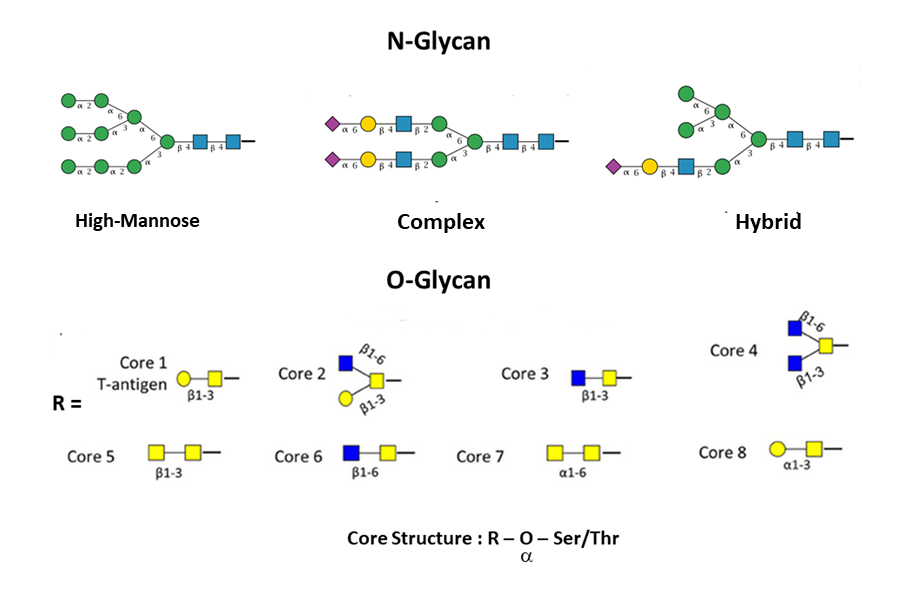
Branched glycans attached to proteins are divided into two main groups: N-linked and O-linked. In the former group, glycans are attached to an asparagine which has to be located in a specific consensus sequence, usually Asn-X-Ser or Asn-X-Thr (in rare cases Asn-X-Cys). In the latter group instead, sugars are attached to serine, threonine, tyrosine, hydroxylysine or hydroxyproline (Lauc et al., 2016). N-linked glycans have a common pentasaccharide core (three Mannose and two N-Acetylglucosamine), and they can be classified into three groups: high-mannose, complex and hybrid. On the contrary, O-linked glycans have eight types of cores which start with an N-Acetylgalactosamine.
The collection of all glycan structures expressed in a specific biological system is defined as the glycome (Packer et al., 2008). In analogy with genomics and proteomics, the systematic study of the glycome is called glycomics. In contrast to proteins, glycans cannot be directly predicted from a DNA template. Also, technical difficulties to correctly determine their complex and branched structures are the reasons why glycomics is lagging far behind other “omics”.
A typical glycomics experiment releases and catalogs all the glycan structures present in a cell, tissue, etc. using techniques like mass spectrometry. In a more sophisticated version of this experiment, glycans are analysed while still attached to trypsin-digested peptides (glycoproteomics experiments). In addition to technical difficulties in elucidating complete structures, glycans are studied separately from their environment losing all the information about the actual landscape (Varki et al., 2010). Although qualitative techniques are improving, the quantitative aspect remains somewhat untouched, since quantitative experiments are still bound to composition more than structure elucidation.