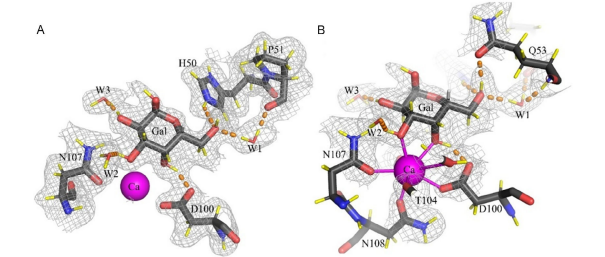
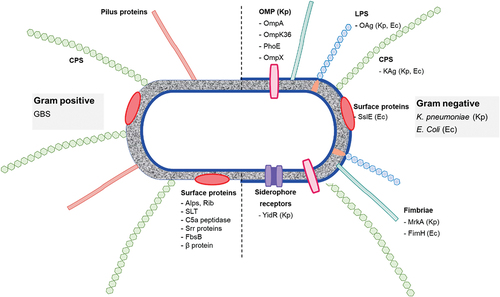
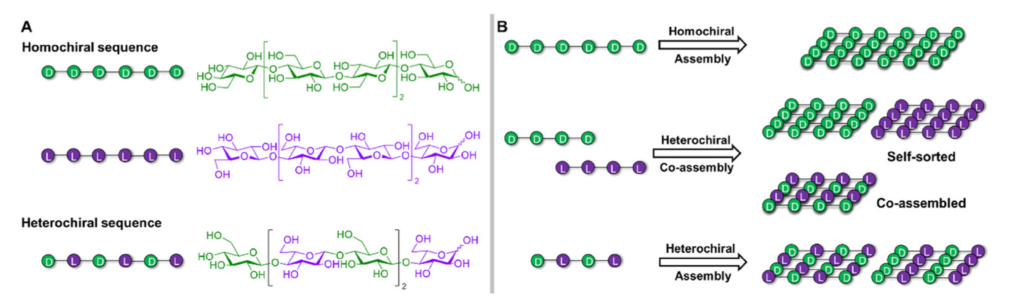
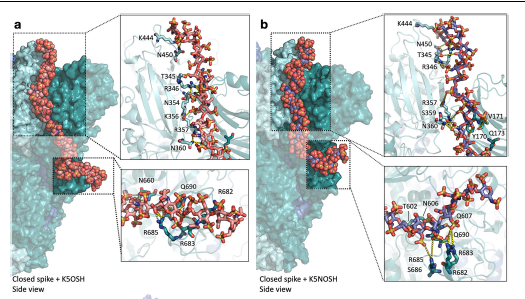
Protein glycosylation is the most complex and prevalent post-translation
modification in terms of the number of proteins modified and the diversity generated. To understand the functional roles of glycoproteins it is important to gain an insight
into the repertoire of oligosaccharides present. The comparison and relative quantitation of glycoforms combined with site-specific identification and occupancy are necessary steps in this direction.
Computational platforms have continued to mature. They assist researchers with the interpretation of such glycomics and glycoproteomics data sets. However, support dedicated workflows and users rely on the manual interpretation of data to gain insights into the glycoproteome. The growth of site-specific knowledge has also led to the implementation of machine-learning algorithms to predict glycosylation which is now being integrated into glycoproteomics pipelines.
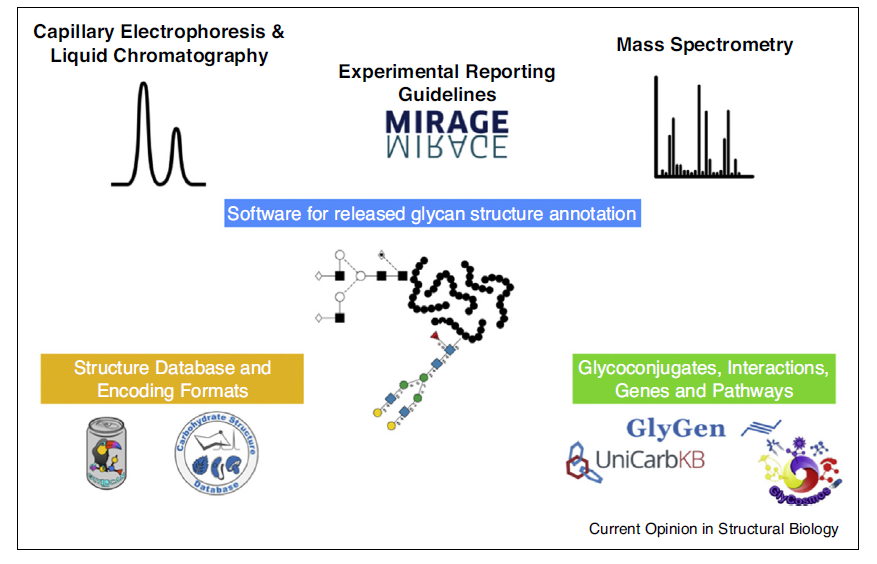
The review describes advances in software applications, databases and reporting guidelines with a focus on released glycans. It describes commercial and open-access databases and software with an emphasis on those that are actively maintained and designed to support current analytical workflows.